Prediction markets are only as good as their referees – and the confidence people place in them.
Referees decide whether any prediction happened or not by the time set. That determines who wins, who loses and whether the price signals are finely tuned to the odds that the predicted event will happen, instead of being distorted by speculation that referees won’t judge accurately. The referee system has to be accurate and reliable.
If it’s perceived as unfair and unreliable, the market eventually loses confidence, integrity, and value. The type of referee system used is a critical design feature.
Augur's referee system operates by decentralized consensus. Consensus, defined as “general agreement” by Webster’s dictionary, is the most basic part of any cryptoeconomic system. Can the nodes in the system come to agreement about reality?
When wagering on a prediction market, after an event occurs you need a way to do the payouts: what actually happened, who won, etc. The most naive way to do this is to just do m of n multisig, which is easily manipulable, falsifiable, and subject to easy bribing. However, in early 2014 both Paul Sztorc and Vitalik Buterin proposed solutions to this problem: why not just ask a lot of people to make the system harder for any one person or group to undermine? Schellingcoin used a weighted bond system and Paul’s Truthcoin used a weighted reputation system that provided some nicer game theoretic incentives making it harder to manipulate (provided you can accurately detect liars).
However, both systems hinge upon the idea of discovering which people told the truth when reporting on payouts, and which ones lied or reported randomly. If you can’t do this, you can’t redistribute reputation to honest reporters, you can’t determine outcomes of events correctly, and two groups of people wrongfully lose money: honest reporters wrongly lose their reputation, and wagerers lose their money because the outcome of an event was determined incorrectly by the consensus algorithm. The entire system falls apart, loses integrity, trust disappears, and people quit using it.
The first proposed system for determining who was a liar and who wasn’t made use of a common statistical technique called principal component analysis (PCA). PCA works by taking each reporter’s “ballot” (the outcomes they reported for a list of events) and organizing them into a matrix, a table of numbers where each reporter is a row and each event is a column. After grinding through the math, you end up with a list of scores for each reporter that tells you how much each contributed to the "noise" in the system. This list is known as the first eigenvector or the first principal component. (Mathematically, these scores are the original centered reports projected onto the covariance matrix’s largest eigenvector.) Each reporter’s nonconformity score tells you exactly how much that reporter contributed to the direction of maximum variance.
This is all a bit abstract, so here’s a simple example: imagine you ask 50 people who the President of the United States is. 49 respond “Barack Obama”, but one deeply misinformed holdout says, “George W. Bush”. The person who said Bush added a lot more to the overall variance than any one of the people who answered Obama!
Why does PCA tell you anything at all about whether or not people are lying? The core idea is that lies are more variable than truths, simply because people who are telling the truth all tend to give the same answer. (This is why police like to isolate suspects from one another, and ask them the same questions -- if their answers don’t match up, they’re probably not telling the truth.) The idea that people tend to converge on the correct answer is similar to the notion of “the wisdom of the crowd”: if you give a large number of people an incentive, such as a cash prize, to answer a question correctly, then, so long as they are coming up with their answers independently, they will make errors in random directions. (For instance, if asked to estimate the temperature in a room, people will over- and under-estimate the true temperature by about the same amount.) In the aggregate, the errors cancel out, and the average answer is uncannily accurate! This effect is amplified when the question is about a real, objective, recent event, and all people are asked to do is accurately report the outcome of that event.
Let’s take a step back. So far, all we’ve done is establish that PCA could plausibly be used to sort out lies from truths. (In physics, claims that sound good but have no evidence supporting them are sometimes referred to as “hand-waving arguments”.) Put another way: it sounds great! The idea passes the laugh test, and deserves further investigation. As Cuba Gooding, Jr. might say, “Show me the data!”
Mr. Gooding is exactly right: if we want to claim that this really works -- on real people with real money at stake -- it’s absolutely imperative for us to present verifiable evidence that it works the way we say it will. After all, what if we blindly implement this method, and it turns out that PCA does not, in fact, accurately detect liars? Well, we’d end up with miscalculated outcomes (“this piece of junk says that Mitt Romney won the 2012 election!”), incorrect payouts (“I bet on Obama, and Obama won, and somehow I lost my money!”), and -- last but not least -- dedicated users who’ve wasted time and effort honestly reporting the outcomes of events losing their Reputation.
Simply put, it would be a disaster, and our entire system would fail. And, as we discovered a couple months ago, this is exactly what happens when you try to use PCA as a lie detector.
I didn’t discover this until May. We had previously been testing Jack’s modifications to Truthcoin consensus to use multiple large components (instead of only the first one) to determine contributions to variance. That allowed us to account for more of the variance (read: noise added by liars) instead of a small fraction of it. Using only one component doesn’t explain as much of the variance added by various reporters in the system.
We were comparing it in simulations (back in March) to the original PCA algorithm for consensus proposed in the Truthcoin paper. It did do better in simulations, but these simulations were comparative, meaning that they were in relation/reference to the original algorithm. In reality, they were less inaccurate than a fundamentally inaccurate system, but not accurate.
Fast forward to May, when there was a debate on Reddit about the merits of both the original Truthcoin algorithm and the modified multiple-component algorithm. I asked if anyone had evidence that the original algorithm worked better and was told that evidence was not needed and any data supporting the original algorithm wouldn’t be published. I responded with: “Imo in cryptoeconomics blindly following anything without verifying isn't a good idea. I'm not willing to use either algo without sufficient evidence. Even the greatest scientists still have to publish sufficient evidence for their claims.” Potentially, we’ll be dealing with people’s lives and livelihoods here. A working consensus system is imperative. So, I decided to investigate things myself.
I first looked at the old set of tests in the Truthcoin repository on Github (https://github.com/psztorc/Truthcoin/blob/master/lib/consensus/Tests.Rmd) and ran them on both algorithms. I discovered that in real life scenarios they both performed pretty poorly. For instance, a simple report matrix like this:
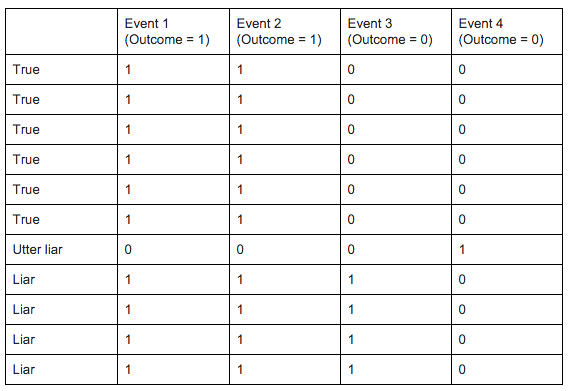
gets interpreted incorrectly by PCA. Note: there is a way to occasionally remedy issues like this by taking the “variance” scores and subtracting the max or adding the absolute min, but sometimes the scores themselves are incorrect, in which case it’s unfixable (all the ones I discuss below are of the “unfixable” type.
So let’s take a closer look at the table above:
Here we have four liars, one huge liar, six honest reporters, and four events they’re reporting on each. The first event’s proper outcome is yes (one), the second is yes, the third is no, and the fourth is no. So pretty clearly even a human can tell what should happen here: the true reporters with ballots of (1,1,0,0) should gain reputation, the “utter liar” should lose the most, and the liars should lose reputation as well. Each reporter starts with 0.09091 or 9.091% of reputation in this case. After PCA detects variance contributions and redistributes reputation, liars get 0.09432 rep each (gaining reputation), the utter liar (or slacker) gets 0.08182 and the honest reporters actually get less: .09015 rep. Sometimes Jack’s “big-five” algorithm does a bit better than the original PCA algorithms, but it still wasn’t accurate enough (“Other than that, how was the play, Mrs. Lincoln?”). This is consensus, with the exception of >51% Byzantine actors and impossible edge cases, things like this shouldn’t be happening. Here we have these “consensus” algorithms failing to achieve correct consensus - the correct results - even on the most simplest of tasks.
I took these results and sent them to Jack, he was shocked, and said something along the lines of “Oh those must just be a few edge cases.” I ran through the rest of the examples in the Truthcoin repo by hand and both of these PCA algorithms each failed on nine of them. I went back to Jack, and he decided to try something different: he ran simulations on the original PCA algorithm and the modified PCA algorithm in isolation. These were no longer comparative studies (as previously we had been assured the original algorithm was thoroughly tested). In the independent sims each algorithm did quite poorly. Even for quite obvious scenarios they reported the wrong outcomes and redistributed reputation improperly a decent amount of the time (around 5-10% from the examples I remember) and upwards as the situations got less obvious (meaning, in worst case scenarios you had liars gaining 30-40% reputation, and honest reporters losing the same).
For Augur, a consensus failure rate of even 1% is unacceptable.
This was unfortunate, but Jack had some ideas for alternative consensus algorithms a while back: the idea was, essentially, why not use a clustering algorithm? Clustering algorithms essentially take a bunch of data and separate it into “clusters” or groups of similar items. So there may be, say, 3 clusters for an example report matrix: honest, liars, and people who just reported randomly. This makes intuitive sense, but has a few problems.
Jack implemented modified versions of consensus using two popular clustering algorithms, hierarchical clustering and k-means clustering, and found that in simulations, k-means did noticeably better than PCA, and hierarchical clustering's results were nearly perfect. The problem is, both k-means and hierarchical clustering are expensive (in terms of both time and computer processing power needed). K means is O(n^2) and hierarchical is O(n^3). For those that don’t know, a short brief on O notation: let’s say you have a task and it is O(n), let’s say it takes one second to run the task on one item. If we have 10 items, it should take about 10 seconds. For O(n^2) it’ll take 100 seconds for 10 items, and for O(n^3) it’ll take 1000 seconds for 10 items, quite a drastic increase in time complexity! There are ways to speed them up, but not a whole lot. Each item also takes a while to run through with these algorithms.
Another problem with them is traditionally, they wouldn’t stay 100% incentive compatible with the game theory behind reputation. The great thing about PCA is it has “variance” scores that can be used to penalize people who stray from the truth, except, many times those scores are just wrong. I wanted to both maintain this benefit of proper, precise penalization whilst getting correct variance scores to use to penalize liars accurately. It turns out there’s a way to do both those things.
So here’s what the ideal algorithm would:
- be linear time or lower computation (10 items takes 10 seconds, 100 takes 100 seconds), meaning it’s cheaper to compute
- penalize reporters who are away from the truth
- maintain incentive compatibility with reputation game theory (by penalizing people similar to the way PCA scores do, but accurate, which also provides some nice benefits to limit p+epsilon attacks)
- have greater precision and accuracy than PCA, and accuracy in isolation of any comparative studies (e.g. stands on its own as a solid solution).
So how the heck do we do all that? Well, I read in an academic paper on clustering that the easiest way to figure out which clustering algorithm is best for your situation is to simply… try them all. I got a bunch of python clustering implementations and tested them out, and none really worked better than hierarchical clustering.
I finally got down to the last algorithm listed on the cluster analysis Wikipedia page: https://en.wikipedia.org/wiki/Basic_sequential_algorithmic_scheme. It seemed ridiculously simple, and I had opened a tab from a NYU class’s notes discussing this scheme a few nights prior, but sort of ignored it. It didn’t really seem intuitively like it’d work for our problem. But I decided what the heck, I’d implement it. I wanted to implement my own implementation of one of these anyway to understand them better, and this is the one I chose. I finished it that evening and ran the first test the next day.
It beat PCA, hierarchical clustering, and k-means on the first test case.
The way BSAS works is you first need to create a function called a distance function, which we’ll use later. The simplest one that works best in my experience is Euclidean distance. It’s pretty simple: sqrt(sum((v1-v2)**2)). v1 is one cluster’s weighted mean ballot (basically, what’s the average report in this cluster, weighted by reputation) and v2 is the cluster you are comparing it with. Now that we have that implemented we need one additional helper function, one to calculate the weighted mean for a cluster. It takes a cluster and for each event takes each reporter’s report in that cluster, multiplies it by reputation, and adds them up, then divides by the total reputation in the cluster.
Now let’s implement the actual clustering algorithm. We want this function to have two inputs, a list of ballots reporting on the outcomes of events and a list of reputation for each reporter’s ballot. Now, for every ballot, we do the following:
- Record the most similar cluster to the current ballot we’re examining (initially this will be “None”)
- We do this by recording the distance between every cluster’s mean ballot and the current ballot using the distance function
- Save the cluster with the shortest distance between itself and the ballot as well as the actual distance value
- If the distance between the most similar cluster and the current ballot is less than a defined threshold (.5 works really well) then add that ballot/reporter to the most similar cluster and recalculate that cluster’s mean ballot vector
- If it’s not within the threshold, create a new cluster with that ballot in it
- We’ve now clustered all the reporters
However, I had all these extra clusters. Way more than hierarchical or k-means came up with. I needed a way to examine a cluster and determine, how much did people report away from the truth in this cluster? And beyond that, which of these clusters was the honest one? Hierarchical clustering pretty much hands you these answers (or at least its interpretations of them). I’d have to elicit this info myself. I started with the idea that the largest (weighted by rep) cluster had the most similar people/reporters in it and that that one was the most honest cluster. The core idea still being the same, honesty would surface, and irreputable reporters would tend to be in their own clusters, or clusters with not many other reporters. They’d contribute too much to the variance to be included in the main cluster. With this, the only way people could break the system successfully is if they did a 51% attack in cohesion which we discourage through a simple commit and reveal.
So now that we have our honest cluster, all that’s left is to find out how far the other clusters’ reporters were from the honest cluster and penalize them accordingly. The way we determine this is by using the distance function. We then record distances for all the reporters from the honest cluster. Now the further a reporter is away, the more he or she should be penalized. There’s a few ways to do this, the naive simple way would be to just do 1/(distance + epsilon (a small number)). This ensures that 0 distance reporters (truth cluster) don’t cause a divide by zero error. However it’s a really harsh function and creates pretty odd results. The other two functions are 1 / (1 + d[i]) ^ 2, which was my favorite because it penalizes liars quadratically away from the truth and 1 - x/maximum(x). After running a bunch of simulations, the one that seems to perform best is 1- x/maximum(x), with maximum(x) being the maximum distance / reporter who added the most to the variance / the biggest liar. So they’d end up with 0.
We then normalize (make it so they add to one) these values after running them through 1-x/maximum(x) and that’s the new set of reputation!
This algorithm is only 87 lines of Python code, runs in linear time (meaning it’s cheap), and penalizes reporters that stray from the truth. But does it determine the truth correctly? And does it actually penalize liars and reward honest reporters?
The first thing I did was run this algorithm on all the old Truthcoin example tests. It got every one right even when the old PCA algorithms got them wrong! There was one it initially got wrong, but I discovered there’s a way to account for that scenario (when a bunch of people report almost randomly) that involves modifying one adjustable parameter in the algorithm, which is, what is the maximum distance required for a report to be within to be considered a member of a cluster? This should probably increase slightly, perhaps logarithmically, with the number of events; further testing will tell us more.
Let’s look at the reputation vector from the new clustering algorithm for that previous case above as an example: liars got 0.0549 rep each, the “utter liar” got 0, and the honest reporters got 0.13 rep each. Much better! If you think the liars were penalized too harshly, this can be remedied by some smoothing or using a milder distance function like 1 / (1+d)^2.
There are only 40 or so test cases in these examples though. So, let’s turn things up a notch and run some Monte Carlo (https://en.wikipedia.org/wiki/Monte_Carlo_method) (i.e., randomized numerical) simulations to simulate the consensus process.
In reality, there is an essentially infinite amount of detail that could go into simulating event consensus. Our goal was to set up coarse-grained Monte Carlo simulations that distill event consensus to its essential driving factors.
We set up our simulations as follows. (Our simulation code is written in the scientific computing language Julia; like all Augur Project code, our simulations are 100% open-source and are freely available at https://github.com/AugurProject/Augur.jl.) Each simulation has a number of events and a number of reporters, which are both fixed. A time step is defined as a completion of event consensus. Our simulations are randomized in two important ways, once during the initial simulation setup, and once in between each time step.
- Before the simulations begin, each reporter is assigned a random number between 0 and 1. (Unless otherwise noted, all random numbers are sampled from a uniform distribution on [0,1).) This value is the reporter’s honesty. If honesty is below a certain cutoff, then the reporter is designated a “liar”. The cutoff is an adjustable parameter. Since honesty is sampled from a uniform distribution, the cutoff is just the expected fraction of reporters that will answer questions incorrectly.
- Each reporter is also assigned an initial amount of Reputation, which is sampled from a power-law distribution, roughly mimicking the shape of most real-world wealth distributions, P(R;a)=a*R^(-1-a) , where R is the Reputation owned by the reporter, alpha is an adjustable parameter setting the large-R decay to zero, and P(R) is the probability of a Reputation value equal to R. We set alpha = 3. This reflects an initial distribution with most Reporters owning just a small amount of Reputation, as well as a few wealthy “whales” that individually own a lot of Reputation.
- Before each consensus “round” starts, a list of events, and their associated correct answers, is generated. This list constitutes the objectively observable reality for the simulations: just as in the real world, some measurable event has taken place in the simulated world, and the reporters are tasked with entering the outcome of these events into Augur.
- Honest reporters simply submit a perfect copy of the correct answers: they looked up what actually happened, then dutifully reported that outcome to Augur. The reports submitted by dishonest reporters depends on the simulation parameters; in the simplest simulation type, dishonest reporters simply enter reports at random. They also have a small chance of simply copying another reporter’s ballot. This small chance is another adjustable parameter, gamma. In the simulations shown below, we set gamma = 0.33.
As with most simulated work, it is crucial that we think carefully about exactly what we’re looking to get out of our simulations -- especially true since we’re a non-profit organization with limited computational resources at our disposal!
With this in mind, what situations do we not need to simulate? Clearly, if there are > 50% honest reporters, then the task of figuring out who is lying becomes trivial: each event can be considered separately, and the most common answer will always be correct. So, we can be confident that -- for random simulations -- we can safely ignore situations where there are over 50% honest reporters. In these circumstances, we are essentially guaranteed to do well, provided that we have selected a half-decent (or, at least, non-insane) consensus algorithm.
The first order of business is to make sure that the algorithms we’re investigating are, in fact, non-insane. So, we’ll use the first group of simulations to do a quick “sanity check”. It is clear that the easiest incorrect reports to filter out should be reports submitted by lazy and/or uninformed people who simply enter answers at random; i.e., white noise. Any supposed “lie detection” algorithm that cannot filter out simple white noise has failed, and is not worth spending more time on.
How can you determine whether or not a lie detection algorithm is any good? Recall that, in our simulations, we know what the correct answer is supposed to be -- this has to be the case, if we’re to have any hope of intelligently evaluating our simulations’ results -- and we also know the “labels” of the reporters. (That is, we know a priori whether or not people are lying!) Since we have this information, the easiest way of evaluating our proposed lie detection algorithms is to ask whether the simulation -- which does not know these things a priori -- is able to accurately punish liars.
To investigate this, we track the changes in each reporter’s Reputation over many consecutive rounds of consensus. By using each consensus round’s updated Reputation as the input into the following round, we can see whether the total percentage of Reputation held by liars increases or decreases over time. As explained previously, below 50% noise -- “noise” being the percentage of reporters giving random answers -- both algorithms can be expected to reliably punish liars.
Not wanting to belabor the obvious, 55% noise seems like a reasonable starting point: it should still be trivial, but not absolutely guaranteed. Each algorithm should break at a sufficiently high noise level. The noise level where the algorithm breaks gives us a way to measure the algorithm’s statistical power. That is, if people are lying, how likely is it that they’ll be caught by our lie detector?
Next we will go over several plots which show our results. In these plots, each data point is an average across 100 simulations, with error bars representing +/- standard error of the mean. Each simulation includes 50 events at each time step, which are being reported on by 100 reporters. Each simulation continues for 100 consecutive time steps. To ensure a fair comparison between different algorithms, the events being reported on, the identities (labels) of the reporters, and the reporters’ initial Reputation values are identical across algorithms.
First, here is a plot tracking the percentage of Reputation held by liars over time. In this plot, a curve that decreases over time is good: liars’ Reputation should be redistributed to honest reporters over time, and (in the long run), liars should end up with no Reputation at all. So, we’d like to see curves that drop down to zero quickly!
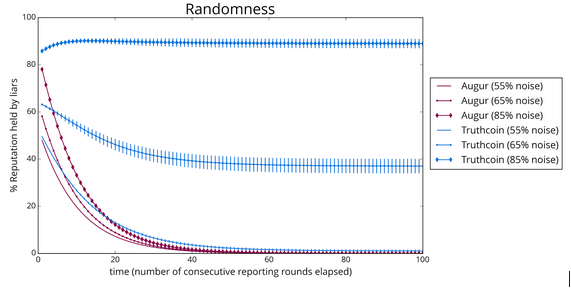
As expected, both Truthcoin’s PCA-based algorithm and Augur’s clustering algorithm reliably punish liars in the presence of 55% noise. However, turning up the noise level to 65% causes a significant failure in Truthcoin, as it allows liars to hold 40% of the total Reputation, and at 85%, it fails catastrophically, with liars stably holding about 90% of all Reputation! Augur fares much better, and it handles the higher noise levels without difficulty. In fact, it is barely affected even at 85% noise: even here, its time trace still displays a rapid exponential decay to zero.
In addition to tracking liars’ Reputation percentages, an informative time series measurement is simply the percent of events for which each algorithm gives the correct answer. Again, our primary interest is in what happens over many consecutive rounds of consensus. Event outcomes are calculated by weighting reporters’ reports with their Reputation value, so, over time, a good event consensus algorithm should “learn” to weigh the honest reporters’ reports more heavily:

As with our direct measurements of Reputation percentages, both algorithms handle 55% noise with no difficulty: 100% of their answers are correct. Augur’s clustering algorithm maintains this performance even at 85% noise. By contrast, Truthcoin begins to have noticeable trouble at 65% noise, although it still gets 3 out of 4 outcomes right. At 85% noise, Truthcoin’s performance has deteriorated significantly: it only provides correct answers for 35% of events. These results suggest that, while PCA is a generally very useful statistical technique, it may simply not be well-suited to the problem of event consensus. It fails to meet Augur’s standard as a referee system for a prediction market.
An alternative explanation might be that, while Truthcoin consensus happens to do poorly in the presence of lots of white noise, it might perform better when presented with more structured reporting data. One way to investigate this possibility is to modify our simulation set-up a bit, so that the behavior of “liars” is a bit more like actual human liars (rather than simply being lazy). It seems reasonable that dishonest reporters could clump together into “conspiracies”, which might represent a reporter and all the people she knows in person, or all her friends from an Internet group. And, since they’re conspiring together, all reporters in a conspiracy give the same set of (typically incorrect) answers.
In this modified simulation set-up, the collusion parameter, gamma, is now the probability that a dishonest reporter will join a pre-defined group of other dishonest reporters. We ran simulations using this modified set-up. In our simulations, we set the number of available “conspiracies” (somewhat arbitrarily) to 5. (A more involved model of conspiracies might make use of, for example, growing preferential attachment networks.) Here are our results:
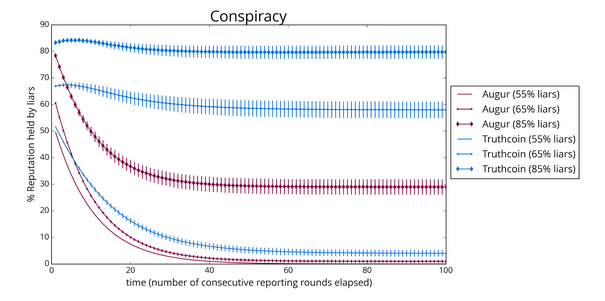
“Conspiracy” is a significantly more challenging scenario than simple randomness, and this is reflected clearly in our results! First, note that while Augur clustering continues pass the 55% and 65% “sanity checks”, under these more strenuous conditions, Truthcoin is showing signs of strain even at 55% -- a steady 5-8% of Reputation remains with liars. At 65%, Truthcoin has completely failed, with about 60% of Reputation held by liars. At 85%, Augur’s clustering algorithm finally buckles, ceding 30% or so Reputation to liars, which is not ideal but certainly better than the 80% ceded by PCA based algorithms. The percentage of correct answers provided by each algorithm displays a similar pattern:

As shown above, at 55% liars, Truthcoin’s percentage of correct outcomes slowly decays to about 45% accuracy, and stays there.
Conclusion: despite its intuitive appeal, our evidence shows that Truthcoin’s event consensus system simply doesn’t work. Relying on this mechanism to provide accurate lie detection with users’ money on the line would be quite risky.
At the end of the day, the core questions that a consensus system must get right are: Does it determine the truth correctly? Does it actually penalize liars and reward honest reporters? For Augur's consensus algorithm, the evidence overwhelmingly points to yes for the vast majority of cases.
Note that all of our raw data (and our code) is freely available:
Simulations, statistics & plots: https://github.com/AugurProject/Augur.jl
