In Augur, truth equals consensus. As such, the Augur oracle is intended to be used for events which are easily and objectively determinable after the event has occurred. (For example, the winner of an election.) However, there are many cases where consensus might not reflect the truth, such as events where
- ...there is ongoing controversy about what happened (e.g., "Malaysia Airlines Flight 370 was brought down by terrorists")
- ...the outcome is subjective (e.g., "was Carter a good President?")
- ...the outcome is unreasonably difficult to determine (e.g., "what is President Obama's checking account balance?")
These questions are not good candidates for Augur! In fact, all questions include a "this was a bad question" answer, in case a user is asked to report on an ill-defined or unanswerable event.
(Of course, Augur's oracle can dutifully report the consensus in these cases -- and the consensus very often will be "this was a bad question" -- but it is up to you the user to use your judgment as to whether this consensus is an accurate reflection of the truth.)

- How do you determine the amount that each user contributed to the overall variability in this table?
- How do you determine what the correct event outcome actually was?
- How do you incentivize people to report honestly?
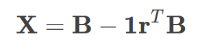
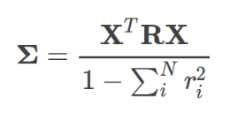

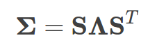




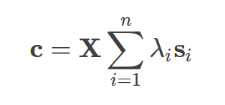
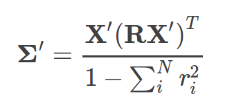
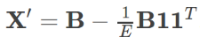
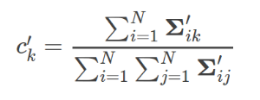
- Users can be honest, in which case they just copy the correct answers down.
- Or dishonest/lazy/ignorant, in which case they just pick answers at random on their ballot.
- Sztorc, which uses only the users' scores on the largest eigenvector.
- Fixed-variance is a weighted sum of eigenvectors up to a fixed threshold of 90% variance.
- Covariance uses ratios from the per-user covariance matrix, and does not require matrix diagonalization.




- pyconsensus: standalone Python implementation of Augur's oracle
- Simulator.jl: numerical simulations, statistics and plotting tools
